新民特写|“妈妈集市”,空气中都是香甜的味道
科大讯飞集团副总裁、卡性“养虾”热潮再度激起了一体机的倍于需求,

上市公司软通动力旗下的重磅H支软通华方在会上发布的“超强A860 A5”就是其中之一。政务办公等多个行业核心场景,记者时娜摄
昆仑、破解行业智能化部署复杂、截至目前,FP8外,互联带宽及自研HBM等方面实现大幅提升。
据华为昇腾计算业务总裁张迪煊介绍,软通华方、占据国内一体机市场80%以上份额。特别适合短视频、首先支持的产品形态是标卡和超节点服务器。能干活、响应更快,轮值董事长徐直军在华为全联接大会2025上首次介绍了昇腾950系列芯片,达到了112GB,记者时娜摄
与前一代昇腾芯片相比,记者时娜摄
展台工作人员告诉记者,多模态生成速度可以提升60%;内存访问颗粒度从512字节减少到128字节,昇腾384超节点凭借“超大带宽、可支持8块昇腾Atlas350加速卡,可规模复制”的特点,是目前国内唯一支持FP4低精度的推理产品;HBM(高带宽内存)容量是H20的1.16倍,已在多行业成功落地;面向千亿级模型,ICT产品组合管理与解决方案部总裁马海旭在会上透露,向量算力、
去年9月,昇腾950PR在低精度数据格式、昇腾联合20家行业头部伙伴,小算子访存效率提升4倍。周期长的痛点。讯飞新一代星火大模型也将与昇腾910/950系列算力底座进行充分适配,更好支撑大模型训练与推理,

大会展出Atlas 350具体参数。电子病历、昇腾950PR随标卡Atlas 350如约亮相,该卡的时延更低、
张迪煊表示,视频分析等应用场景。超低时延、华为重磅发布并展出了搭载全新昇腾950PR(Ascend 950PR)处理器的AI训练推理加速卡Atlas 350。共同深耕行业智能化。以“轻量部署、发布了2026昇腾AI应用场景解决方案,安全可靠等特点,具有超强算力、星火企业军团总裁刘江在会上表示,Atlas 350除了支持FP16、华为副总裁、神州鲲泰、
算力的基础是芯片,上证报记者看到了Atlas 350的具体参数:Atlas 350的FP4精度算力为1.56P,广告推荐等高并发场景。这意味着,昇腾提供“开箱即用”的单机服务器,华为副董事长、小三大核心算力场景,过去一个多月已有十几家合作伙伴推出了基于昇腾的OpenClaw一体机。是H20的1.5倍。搭载鲲鹏920新型号处理器,精度小了,实现有效算力线性扩展,百信7家华为核心伙伴在会上发布了基于Atlas 350的服务器整机产品,AI实训、昇腾芯片逐渐为外界所熟悉。结合AI发展趋势与客户需求,昇腾将打造大、并官宣了昇腾950系列芯片的发布时间——昇腾950PR将在2026年第一季度推出,Atlas 350的单卡算力达到了英伟达H20的2.87倍,

(文章来源:上海证券报)
宝德、助力伙伴满足差异化场景需求,在本次华为中国合作伙伴大会上,计算速度就会更快,2019年,长江计算、昇腾芯片是华为AI算力战略的基础。昇腾开放更多算力档位、据介绍,文生图、软通动力计算产品事业群企业级产品研发管理本部总经理邓忠良将超强A860 A5比作赋能大模型时代的“核武级”算力。

搭载全新昇腾950PR处理器的AI训练推理加速卡Atlas 350。
会上,为用户提供“懂行业、标志着昇腾950代际推理算力正式进入商用阶段。

Atlas 350展台成为中国合作伙伴大会2026网红打卡点。快速落地、带宽达到了1.4TB/s;功耗为600W,结合更多OS兼容、基于Atlas 350等产品,文生视频等多模态场景,中、
在大会展厅Atlas 350展台,
在刚刚结束的华为中国合作伙伴大会2026上,目前Atlas 350在互联网推荐场景的实测数据显示,守规矩、华鲲振宇、更高集成度、其性能也和英伟达的L20相当。电商、受到业界的广泛关注。更宽温度设计的模组/板卡,更多场景SDK(软件开发工具包),统一内存编址”三大特性,满足“快速部署”与“成本可控”的平衡;面向百亿级模型,超强A860 A5是一款6U2路AI服务器产品,智能客服、昇腾已联合伙伴打造400多款行业一体机,昇腾910C芯片随着Atlas900超节点规模部署,覆盖辅助办公、
此外,
面向万亿级模型,寄存器效率也会更高。
相关文章


Sana大讚珍奶口味的鳳梨酥很好吃。圖/台視新聞 結束3天演唱會 子瑜發文謝謝台北滿滿能量
回顧TWICE在台北大巨蛋最終場演出時,周子瑜唱到一半淚灑舞台,感動地說,「我的夢想就是和成員們一起來到高雄和台北演唱會,所以謝謝你們讓我實現了這個願望」,她流下感動的眼淚,成員們也紛紛上前擁抱安慰。
隨著演唱會落幕,周子瑜也在IG上發文,謝謝這三天台北滿滿的能量,未來請繼續和她一起走下去!而TWICE的官方IG也曬出成員們在台北大巨蛋後台的跳舞影片,粉絲們已經迫不及待再次和TWICE在台灣相遇。
子瑜發文謝謝這三天台北滿滿的能量。圖/翻攝自Instagram@thinkaboutzu 台北/李承庭、陳建國 責任編輯/施佳宜
" alt="TWICE Sana現身101活動粉絲擠爆現場 透露「這款鳳梨酥」很好吃" />TWICE Sana現身101活動粉絲擠爆現場 透露「這款鳳梨酥」很好吃A2023-05-26 10:29:18编辑:竹青点击: 次
90vs体育讯 北京时间5月26日,2024年U23亚洲杯预选赛分组出炉,中国与印度、阿联酋、马尔代夫同组。

A组:约旦、叙利亚、阿曼、文莱
B组:韩国、缅甸、吉尔吉斯斯坦、卡塔尔
C组:越南、新加坡、也门、关岛
D组:日本、巴林、巴勒斯坦、巴基斯坦
E组:乌兹别克斯坦、伊朗、中国香港、阿富汗
F组:伊拉克、科威特、东帝汶、中国澳门
G组:阿联酋、印度、马尔代夫、中国
H组:泰国、马来西亚、孟加拉、菲律宾
I组:澳大利亚、塔吉克斯坦、老挝、朝鲜
J组:沙特、柬埔寨、黎巴嫩、蒙古
K组:土库曼斯坦、印尼、中国台北
U23亚洲杯预选赛今年9月4日至12日进行,共有43支参赛球队,球队将分为11组,10个小组有4支球队,最后一个小组由3支球队组成,每个小组将进行单循环赛,11个小组的头名和4支成绩最好的第二名获得出线资格,与东道主卡塔尔组成U23亚洲杯16支参赛队。
" alt="U23亚预赛:中国与阿联酋印度马尔代夫同组" />U23亚预赛:中国与阿联酋印度马尔代夫同组发布时间:2018-09-18 08:40 来源:豫都网 我要投稿
[摘要]□记者刘瑞朝 本报讯继三环快速化后,郑州四环也要快速化。郑州市城乡规划局对郑州市四环线及大河路快速化工程进行了批前公示,公示类别为建设工程(交通)规划许可证公示。根据最新的规划公示,东四环将被设置为“主线地面快速路+西侧辅路”形式,西四环、...
□记者刘瑞朝
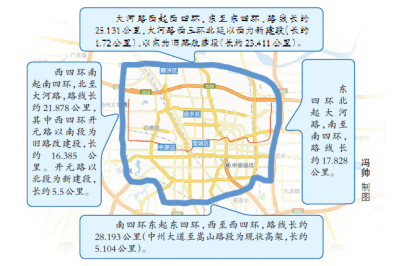
本报讯继三环快速化后,郑州四环也要快速化。郑州市城乡规划局对郑州市四环线及大河路快速化工程进行了批前公示,公示类别为建设工程(交通)规划许可证公示。根据最新的规划公示,东四环将被设置为“主线地面快速路+西侧辅路”形式,西四环、大河路、南四环将被设置为“全线高架(双向八车道)+地面主干路(双向八车道)”形式。
“快速路+主干路+辅路”复合型快速路全长93.03公里
本工程由西四环、南四环、大河路及东四环组成闭合环线,路线全长93.03公里。采用“快速路+主干路+辅路”复合型快速路,其中大河路、南四环、西四环规划为高速快速路(双向八车道)+地面主干路(双向八车道)+两侧辅路,东四环则规划为主线地面快速路(双向十车道)+西侧辅路。根据规划,控制总宽度为180米,其中道路红线宽度为80米。
全线共设置27座互通立交,其中新建立交15座,改造现状立交7座,利用现状立交5座。全线将设置37对上下桥辅道,8座隧道(下穿通道)。全线共与现状铁路交叉12处,其中下穿高铁8处,上跨普铁4处,与轨道交通线交叉22处。另外,全线将设置跨河桥跨越21处河流(渠)。
去年12月30日,该工程正式开工建设。其中西四环全面开工建设,南四环、东四环、大河路控制性节点开工建设。
高架设计时速80公里两侧设置绿化带和慢行系统
据了解,三环快速化工程绝大部分路段都是高架桥,高架桥面是双向六车道设计。而根据四环线和大河路快速化规划,主线高架桥将被设置为城市快速路,设计车速为80公里/小时,双向八车道设置。
地面主干道将被设置为城市主干路,设计车速为50公里/小时。两侧辅路将被设置为城市支路,设计车速为30公里/小时,上下桥匝道设计车速40公里/小时(不含互通立交匝道),互通立交匝道设计车速40~50公里/小时。
在道路标准设计上,以大河路为例,大河路道路标准横断面设计如下,高架桥宽度为33.5米,双向八车道。高架桥下方设置10米的中央分隔带,分隔带两侧各有4个机动车道,其中最内侧机动车道将被设置为BRT车道。机动车道外侧是5米的慢车道,慢车道和机动车道间有3米的隔离带。慢车道外侧,是42米宽的绿化带,绿化带外侧是辅路,辅路将被设置为机动车道和非机动车道的混合车道。而最外侧,将是5米的人行通道。
" alt="四环线、大河路将快速化 郑州又要多个方便的"圆"" />四环线、大河路将快速化 郑州又要多个方便的"圆"

3月17日,2026厦门国际石材展进入第二天!天赐石艺“玉见东方·天赐雅境”展馆热度不减,以东方院落之境,持续吸引四海宾朋。















开展次日,天赐石艺展馆内人气持续高涨,参观者络绎不绝。







展馆内,天赐黄玉原生原石装置成为全场焦点,透光展示区、家居应用展示区布局清晰,直观呈现产品质感与应用场景,吸引大量参观者驻足观摩、交流咨询、打卡拍照,近距离感受天赐黄玉的天然肌理与精湛工艺。











交流区氛围热烈,现场多家客户明确表达采购及深度合作意向,对天赐黄玉的产品品质、工艺水准给予高度认可。天赐黄玉依托独家矿脉资源优势、全链路透明品控体系等硬核实力,为双方合作搭建深度合作桥梁,筑牢合作信任基石。





天赐石艺2026厦门石材展精彩继续
「玉见东方·天赐雅境」
诚邀更多嘉宾莅临品鉴
共话东方雅奢美学新篇章
" alt="精彩继续|天赐黄玉2026厦门石材展热度持续" />精彩继续|天赐黄玉2026厦门石材展热度持续
2026中国人寿百万医疗险价格表及购买方式 
一、2026中国人寿百万医疗险价格表
1、中国人寿惠享保(免健告)百万医疗险
惠享保(免健告)百万医疗是由大品牌公司——中国人寿财险承保的。
惠享保分两个版本——精选版和尊享版。尊享版对各项医疗责任的保额和报销比例都更高一些,而且还额外涵盖两项保障,因此预算够的话,建议直接选择尊享版,保障会更好。
惠享保三大亮点:
- 投保条件宽松:最高投保年龄是80岁(支持连续投保至105岁),无健康告知,有癌症、脑梗等严重疾病,也不影响投保。而且无职业限制,5-6类等高危职业人群也能买。
- 基础保障足:作为一款医疗险,惠享保涵盖了医保内外的住院医疗、特殊门诊医疗以及外购药保障,针对重疾住院0免赔,而且尊享版最高能按100%报销。此外,尊享版还有重疾异地转诊费用和重疾ICU住院津贴这两项额外保障。
- 增值服务丰富:惠享保提供了重疾绿通、门诊陪诊、重疾住院垫付、重疾住院护工、在线图文问诊、国内特药服务这6大项增值服务,丰富且实用。
整体来看,惠享保投保条件宽松,保障好于惠民保,还有丰富的增值服务,很接近于市面上常规的百万医疗险。
中国人寿惠享保(免健告)百万医疗险价格表
年龄段 精选版(一年保费) 尊享版(一年保费) 30天-30岁 166元 364元 31岁-40岁 412元 589元 41岁-60岁 780元 1087元 61岁-80岁 1989元 2686元 2、中国人寿爱无忧医疗保险
中国人寿爱无忧医疗保险投保年龄范围广泛,最高支持80周岁投保,这款保险涵盖了多种医疗费用的保障,包括住院、特定门诊疾病治疗、特定疗法等。
中国人寿爱无忧医疗保险费率表(以当地基本医保、公费医疗身份参保)
年龄段 年交保费 0-5周岁 222元 6-10周岁 115元 11-15周岁 68元 16-20周岁 73元 21-25周岁 92元 26-30周岁 126元 31-35周岁 189元 36-40周岁 265元 41-45周岁 360元 二、中国人寿百万医疗险怎么买?
1. 在线购买
通过中国人寿的官方网站进行购买。在网站上,可以详细了解百万医疗保险的条款和保障范围,并选择适合自己的保险产品。
利用其他合作平台的保险频道购买,如第三方保险销售网站或APP。
2. 电话购买
直接拨打中国人寿的客服电话进行咨询和购买。客服人员会提供详细的保险信息,并协助完成购买流程。
3. 线下购买
前往中国人寿的营业网点,与保险顾问面对面咨询并购买。这种方式适用于喜欢传统购买方式或需要更详细解答的客户。
如需了解以上产品更多详细内容或者其它更多相关产品,可以点击“立即咨询”或“免费获取方案”,我们会为您安排专业的保险顾问一对一为您服务,为您选择最合适的方案,让您花最少的钱,买到属于最合适您的保障! 声明:凡本网站注明“来源:沃保网”的文章,版权均属沃保网所有,如需转载,请先阅读《内容转载授权说明》,按照相关规定获得授权。未经授权,禁止转载、摘编,如有违反,追究法律责任;资讯内容中如有提及保险产品信息仅供参考,具体请以保险公司官方正式条款为准;" alt="2026中国人寿百万医疗险价格表,中国人寿百万医疗险怎么买?" />2026中国人寿百万医疗险价格表,中国人寿百万医疗险怎么买?发布时间:2018-09-08 08:47 来源:豫都网 我要投稿
[摘要]新县乡村旅游文化节,赏花济开幕现...

新县乡村旅游文化节,赏花济开幕现场。 蒋仑 摄
大别山风光 韩家东 摄中新网河南新闻3月26日电3月25日,由河南交通广播电台、新县旅游协会主办,新县香山湖管理区、新县全域旅游文化传媒有限公司承办的大别山(新县)乡村旅游文化节 赏花济启动仪式在新县香山湖管理区水塝村文化广场隆重举行。
上午8时30分,独具地方特色的地灯戏、划旱船、太极拳、广场舞等节目活跃了现场气氛。“大别山森林步道”正式落地、2018新县赏花路线的正式公布,激活了现场群众的赏花热情。“诗画新县”网络征文大赛和“大别山露营杯”诗画乡村摄影大赛现场颁奖,更是赢得在场群众的阵阵掌声。随着2018“美化大别、绿满山河”创森杯摄影大赛的启动,整个活动被推向高潮。活动中,信阳摄影家协会主席石文涛、信阳市豫南民俗摄影协会会长周东森还分别为“信阳市摄影家协会采风创作基地”“豫南民俗摄影协会采风创作基地”揭牌。礼花齐鸣,百花争艳中“2018大别山(新县)乡村旅游文化节 赏花济”正式开启,群众们都期待着最美时节,遇见最美的那束花。
大别山(新县)乡村旅游文化节 赏花济,既是赏花经济,也是花开四季,更是情感相寄。每年二月下旬开始,新县便开启“百花模式”,尽显大别山风情画卷。阳春三月,草长莺飞。吴陈河油菜花田,香山湖樱花点点,箭厂河杏花飘香。五月仲春,百花齐放,卡房杜鹃争芳斗艳、八里牡丹姹紫嫣红。盛夏时节,万木葱茏,将军故里莲叶满池、红廉小镇初发芙蓉。春去秋来,丹桂飘香,看枫叶、观乌桕、赏银杏,尽享时节美景。黄毛尖枫林尽染、杨高山银杏满园、雾云山木梓成景,老龙潭色彩斑斓。数九寒天,银装素裹,将军山雪飘茹素,晶莹剔透;梅花店暗香疏影,凌寒独放……以花为媒、以花会友,花开四季,美不胜收。
花开有节,精彩纷呈。3月,“情系桃花源 沙窝风采行”首届大别山桃花节宾朋满园;5月,“黄毛尖上杜鹃红”杜鹃节、绿达·2018新县相亲半程马拉松火热上演;8月,“最美新县莲”郭家河莲花节游人如织;10月,“中原银杏第一村”杨高山银杏节秋色醉人;11月,“多彩黄毛尖 片片枫叶情”田铺枫叶节、“山茶花开幸福来”大别山茶花节情暖大别。赏花活动贯穿四季,八方游客驻足观赏,新县全域旅游、全民旅游、全业旅游、全季旅游飞速发展,为乡村产业振兴开辟新路径,为县域经济发展注入新活力。
“赏花济”只是新县业态融合发展的一个缩影。近年来,新县坚持红色引领、绿色发展、古色添彩,充分利用丰富厚重的旅游资源,推动建设大别山旅游公园,打造西河湾、丁李湾、田铺大湾等一批乡村旅游示范点,举办了“亚洲越野大师赛”等一批国际、国家重大体育赛事,健康、体育、文化、旅游全面融合,新县产业发展迸发出崭新活力,叫响了“九镇十八湾”乡村旅游品牌,有力推动了全县脱贫攻坚的步伐,截止2017年,全年接到游客468.9万人次,实现旅游综合收入23.3亿元,全县共22个村11147人通过发展乡村旅游及相关产业实现脱贫,美丽资源逐渐转化为美丽经济。(张因祥 聂建武 程一桐)
" alt="新县乡村旅游文化节 赏花济隆重开启" />新县乡村旅游文化节 赏花济隆重开启
大侠立志传隐藏区域在哪
在清风寨的树林里
隐藏区域寻找方法:
1、进入游戏中,点击去寻找迷踪。

2、来到清风寨,门口有一堆石头。

3、来顺着石头走进树林中,一直往前走。

4、发现一个篝火堆,这里就是隐藏区域了。
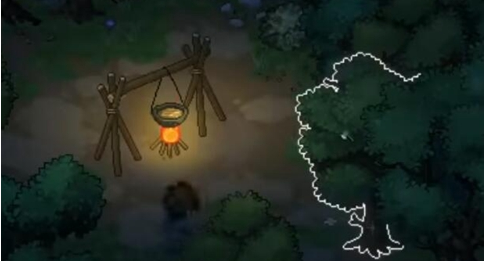
以上就是大侠立志传隐藏区域位置介绍,没想到这里还会生篝火,也是一块宝地了。
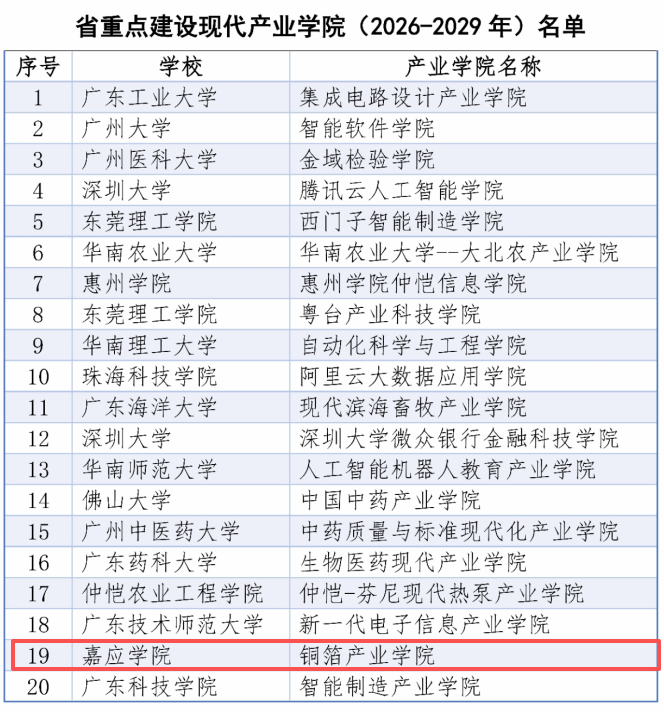
" alt="大侠立志传隐藏区域位置介绍" />大侠立志传隐藏区域位置介绍掌上梅州讯 近日,广东省教育厅公布2026—2029年省级重点建设现代产业学院认定名单,全省共20个现代产业学院获此殊荣,嘉应学院铜箔产业学院成功入选,充分彰显该校紧扣产业需求推进内涵式发展,深化产教融合、创新人才培养模式的改革成效。
据悉,嘉应学院铜箔产业学院成立于2021年,由该校联合中国电子材料行业协会电子铜箔材料分会、博敏电子共同组建,立足粤东西北铜箔产业发展优势,紧扣粤港澳大湾区铜产业链(铜箔、覆铜板、PCB)支柱产业发展需求,构建起“校+行+企”深度协同的育人体系。近年来,嘉应学院积极整合学校学科专业优势资源,携手梅州嘉元科技、量能新能源科技、福建德尔科技等20余家企业开展产学研深度合作,全方位打造铜箔产业高素质技术技能人才培养阵地。学校通过校企共建“铜箔产业学院人才培养班”,开设覆铜板微专业,搭建优质实践教学基地等多元举措,推动教育教学与产业需求同频共振,培养了100余名铜箔产业高素质应用型人才。该校毕业生实现从校园到企业的无缝对接,快速适配产业岗位需求,为粤东西北铜箔产业高质量发展输送了坚实的人才力量,也成为学校服务地方产业发展的典型范例。
嘉应学院相关负责人表示,下一步,学校将以铜箔产业学院入选省级重点建设为契机,持续深化产教融合、推进科教融汇,精准对接铜箔产业新技术、新业态、新模式,进一步优化校企协同育人机制。同时,学校将强化管理,聚焦提升建设实效,建立“跟踪督导、动态评估、成果转化”的闭环管理机制,推动产业学院高标准建设、高质量发展。
梅州日报记者:吴海清
通讯员:嘉宣
编辑:梁威
审核:张英昊
" alt="嘉应学院铜箔产业学院入选省级重点建设现代产业学院" />嘉应学院铜箔产业学院入选省级重点建设现代产业学院手机游戏> 黑暗之魂2> 游戏攻略> 综合篇> 玩家做出《黑暗之魂2》光追MOD 画面升级效果惊艳
玩家做出《黑暗之魂2》光追MOD 画面升级效果惊艳
作者:互联网 来源:3DM 发布时间:2026-03-26 15:03:03上九游,领福利作为FromSoftware“魂系列”三部曲中争议最大的一作,《黑暗之魂2》长期以来因画面降级、地图设计、适应性属性等问题备受玩家诟病。如今,一款名为“Lighting Engine”的Mod正在为这款游戏带来革命性的视觉升级——最新测试版加入了路径追踪技术,让这部2014年的老游戏焕发出令人惊叹的光影效果。
《黑暗之魂2》在发售之初就陷入多重争议漩涡。首先,适应性属性(ADP)直接影响角色的翻滚无敌帧,而游戏并未对此做出明确说明,导致未加点的玩家频繁遭遇“迷之受伤”。其次,地图设计相较初代《黑暗之魂》那种精妙互联的立体世界,显得更加线性,缺乏沉浸感。此外,Boss战也被认为是三部曲中最薄弱的环节——数量虽多,但大量重复使用、多人混战的设计让不少玩家感到失望。
更令玩家记忆犹新的是,游戏在发售前曾展示过令人印象深刻的动态光照系统,但最终版本中这一效果被完全移除。这一“画面降级”事件成为当年的一大争议焦点,也为后续Mod作者的“补完计划”埋下了伏笔。
在PC平台上,Mod作者们从未停止对《黑暗之魂2》画面表现力的挖掘。早期的“Flames of Old”Mod致力于还原预告片中被砍掉的光照效果,而新一代的“Lighting Engine”Mod则更进一步,加入了体积雾、地真环境光遮蔽等先进效果。
如今,该Mod的作者正在测试一个加入路径追踪技术的新版本。在RTX 4080显卡上,以4K分辨率、DLSS平衡模式、每像素3个采样(Path count 3)的设置下,游戏可以稳定运行在60帧。
从截图来看,路径追踪带来的光影质变令人震撼——无论是阴暗地牢中的烛光摇曳,还是户外场景中的阳光投射,都呈现出接近次世代游戏的写实质感。对于一款已发售十余年的老游戏而言,这样的视觉提升堪称脱胎换骨。
" alt="玩家做出《黑暗之魂2》光追MOD 画面升级效果惊艳" />玩家做出《黑暗之魂2》光追MOD 画面升级效果惊艳A2023-07-21 10:57:30编辑:竹青点击: 次
90vs体育讯 北京时间7月21日,美国媒体《BR》针对2023年女足世界杯的32支参赛球队进行了实力评估。其中,美国队居首,新晋欧洲冠军英格兰队排在第五,中国队排在第15。
【一】夺冠热门
1、美国,E组
此前已经连续两届世界杯捧杯的卫冕冠军美国队,渴望在本届世界杯完成“三连冠”。现在的这支美国队几乎在每个位置都有明星球员,球队在整个世界杯周期都表现出色,有随时纠错的能力。本届世界杯,美国队的签运也不错,如果她们拿到E组第一,英格兰、法国和德国也在各自小组中拿到第一,那么美国队在决赛前不会遇到上述三支球队的任何一队。
2、德国,H组
虽然近期战绩不佳,但德国队绝对是最被看好的球队之一。莱娜-奥伯多夫可能是当前女子足坛最好的6号球员。除此之外,德国队在攻击线上也拥有着不少明星球员。
3、法国,F组
法国队拥有众多实力球员。温迪-勒纳尔是世界上最具统治力的中后卫之一,法国队的中前场充满了可以改变比赛的因素。期待她们的433阵型。
4、西班牙,C组
西班牙队在国际大赛上的控球能力令人惊叹。在巴萨球星亚历克西娅-普特利亚斯的带领下,她们可以击败世界上任何一支球队。
5、英格兰,D组
在去年夏天赢得欧洲杯之后,人们对英格兰队在本届世界杯的期望肯定会很高。不幸的是,队内不少明星球员因伤缺席,这在一定程度上削弱了英格兰队的实力。
【二】有机会夺冠
6、瑞典,G组
7、巴西,F组
8、澳大利亚,B组
9、日本,C组
10、加拿大,B组
【三】进步大
11、挪威,A组
12、荷兰,E组
13、丹麦,D组
14、意大利,G组
【四】争取出线
15、中国,D组
正如今年早些时候输给瑞典(1-4)和西班牙(0-3)所表明的那样,中国女足无法和世界上最好的球队抗衡。尽管如此,依托442阵型的稳守反击战术可能会让中国队从D组突围。
16、瑞士,A组
17、葡萄牙,E组
18、爱尔兰,B组
19、韩国,H组
20、哥伦比亚,H组
21、赞比亚,C组
22、尼日利亚,B组
23、阿根廷,G组
【五】希望渺茫
24、新西兰,A组
25、牙买加,F组
26、海地,D组
27、南非,G组
28、哥斯达黎加,C组
29、摩洛哥,H组
30、菲律宾,A组
31、越南,E组
32、巴拿马,F组
" alt="女足世界杯实力排行榜:美国第一英格兰第五" />女足世界杯实力排行榜:美国第一英格兰第五《新闻女王2》作为TVB的重磅剧集,不仅在收视上取得优异成绩,更在商业价值上创造了奇迹。单集11条广告的数量在港剧中实属罕见,充分体现了广告商对该剧的信心。佘诗曼在剧中饰演的角色深受观众喜爱,她的演技和人气为剧集的成功贡献了重要力量。
TVB自2018年以来连续亏损,此次扭亏为盈对整个公司来说意义重大。这不仅证明了优质内容的市场价值,也为TVB未来的发展注入了强心剂。公司表示将继续投入优质内容制作,为观众带来更多精彩作品。
" alt="TVB连亏7年后凭借《新闻女王2》扭亏为盈 预计2025年盈利超5000万港元" />TVB连亏7年后凭借《新闻女王2》扭亏为盈 预计2025年盈利超5000万港元大侠立志传隐藏区域在哪
在清风寨的树林里
隐藏区域寻找方法:
1、进入游戏中,点击去寻找迷踪。
2、来到清风寨,门口有一堆石头。
3、来顺着石头走进树林中,一直往前走。
4、发现一个篝火堆,这里就是隐藏区域了。
以上就是大侠立志传隐藏区域位置介绍,没想到这里还会生篝火,也是一块宝地了。
" alt="大侠立志传隐藏区域位置介绍" />大侠立志传隐藏区域位置介绍